Приёмы составления правильной API документации
Intro
Существует множество подходов написания API документации, и большинство из них автоматизированные: от сбора XML комментариев из кода до создания API из документации с ноля в Swagger или таких инструментах, как Stoplight. Но я бы хотел сделать шаг назад и посмотреть на «картину» в целом, то есть сконцентрироваться не на том КАК мы создаём документацию, а всё-таки ЧТО мы в ней предоставляем.

Смотрите шире
Последние 8 лет я являюсь разработчиком API и потребителем API одновременно. Мне приходилось реализовывать интеграцию одних продуктов в другие через API множество раз: интеграция с ГИС, интеграция поиска и бронирования тревел-услуг, интеграция множества всевозможных ФинТех сервисов, и т.д. Всего я видел не менее 200 различных документаций публичного API и не менее 100 из них мне приходилось непосредственно использовать. Я видел много способов описания API:
- Описания в виде 5 двухсот-страничных PDF документов, каждый из которых в деталях описывал широкий набор взаимозависимых и взаимосвязанных API методов и DTO (Data Transfer Object) объектов;
- Описание в виде трёх предложений в Skype;
- Полноценные динамические веб приложения с собственной аутентификацией и системой прав доступа, внутренней системой а-ля wiki, примерами и инструментами;
- А также автоматически сгенерированные документы на основе XML-комментариев… документация в стиле «отвали»;
На самом деле трудно сказать какой из способов лучше. Ни один не был хорош. Но я и сам разрабатываю API и я прекрасно представляю как сложно составить понятную документацию, которая бы помогала быстро и легко провести процесс внедрения.
Но я подозреваю, что вы, как и я, хотели бы:
- Чтобы ваш API был полезным и широко использовался
- Чтобы не приходилось объяснять одни и те же «простые и понятные» вещи каждому
- Чтобы API выглядело и работало на профессиональном уровне
- Чтобы API было не трудно и не стыдно поддерживать, и расширять на протяжении последующих нескольких лет
Чтобы добиться этого всего нужно следовать всего лишь одному правилу: поставить себя на место потребителя вашего API. Но это сложно сделать и поэтому я решил написать этот пост.
Я покажу простые и, казалось бы, очевидные вещи, на которые стоит обратить внимание при создании API документации. Этого, как правило, не делают многие, но это приблизит вас к целям, описанным выше.
В первую очередь цели
Тот кто собирается использовать ваш API не должен обязательно становиться экспертом в этом:
Потребитель API собирается решать СВОИ, задачи, а не ваши. Бум!
Как разработчик, я всегда держу в голове некую цель, ради которой я копаюсь в чьей то документации или самом API. Как правило, у меня есть техническое задание и в нём чётко сказано, что в первую очередь является признаком успешной интеграции. Например, мне может быть нужно пройти начальную авторизацию у вас на сервисе и дёрнуть один единственный метод из 100 доступных. Да, в дальнейшем, мне может понадобиться большее разнообразие, но не факт и не прямо сейчас.
Другими словами, люди будут искать как решить свои задачи, которые не обязательно ваш API вообще решает, поэтому одна из главных целей API документации: объяснить почему нужно использовать ваше API и какие проблемы оно решает.
В идеале, документ, какого бы формата он ни был, должен в первую очередь описать наиболее простые и вероятные сценарии использования.
Формат
Формат сам по себе не так уж важен для читателя. Вы можете одинаково всё испортить, либо же преуспеть, в любом формате документации. Что более важно, так это насколько много времени я потрачу на чтение и понимание основ использования вашего API. Иными словами, документация может быть и в PDF, и в интерактивном приложении, и в комбинации всех – лишь бы потребитель мог быстро в этом разобраться.
Понятность, удобство навигации и краткость имеют гораздо больше ценности.
Первые три страницы
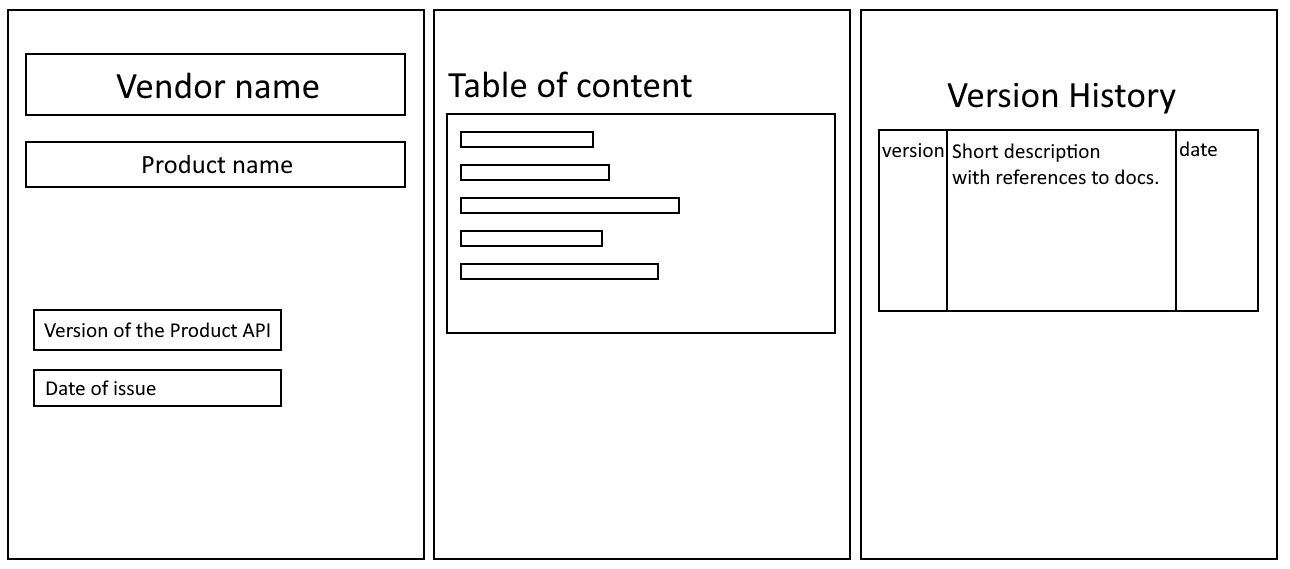
Если потребитель не может за 1 минуту разобраться в структуре вашей документации, значит есть над чем работать.
Вендор
Думаете это очевидно? Как бы не так. Название часто опускается из-за того, что над документацией работали только программисты. Но компании, как живые организмы, исчезают и появляются, объединяются и расходятся, и крайне важно понимать кто отвечает и кто предоставляет данное API. Особенно это касается больших Enterprise компаний, продукты которых часто становятся часто ещё больших продуктов, команды реорганизуются и контакты легко теряются.
Помимо очевидного фактора «кто владелец», важен и коммуникационный фактор: как называется данная интеграция среди всех моих интеграций? Приведу пример большого финансового агрегатора Fiserv, который поглотил не мало более мелких сервисов, и если когда-то мы могли назвать интеграцию с его API просто “Fiserv integration”, то сейчас нужно задуматься какой именно из сотни сервисов мы интегрируем.
Версия
Любой продукт меняется и развивается и крайне важно понимать, насколько свежую версию API потребитель использует. Версию можно пропускать только в редких случаях крайне стабильных продуктов, являющихся стандартом индустрии: примером может служить аутентификация через SAML protocol, у которого тоже есть версии, но стандартом является SAML 2.0, и у неё вот уже много лет не появляется обновлений, а версия 1.1 является Deprecated.
Если пользователем вашего продукта (API – это тоже продукт) будет больше 1го человека, то стоит привязываться к стандартным способам версионирования, например к Semantic Version, с самой первой 0.0.1 версии. Если этого не сделать, то можно обречь себя на долгую и несчастливую поддержку legacy версий. Хороший пример версионных «войн» в Microsoft DotNet Core: https://docs.microsoft.com/en-us/dotnet/core/versions/.
Покажите версию вашего API сразу на первой странице. Добавьте короткое описание того, как вы собираетесь изменять и обновлять ваши версии (если это стандарт, вроде Semantic versioning — достаточно положить ссылку на стандарт).
Содержание
Звучит очевидно, но 50% документации не имеют нормального нумератора страниц, или ссылок на разделы, либо простого содержания. Многие документы сразу описывают листы XML сервисов их парами Request/Response. Для простого и очевидного API это может работать нормально, но не для среднестатистического сервиса с десятком методов. С самого начала потребитель, решающий свою задачу, должен понять что ему нужно читать, а что можно пропустить. Он не должен становиться экспертом в вашем API или вашей документации. Не нужно ожидать, что она будет прочитана от А до Я.
Документ должен покрывать детали там, где это нужно, но скорее всего не с первой страницы. Подумайте лучше о том, как разбить вашу документацию. Можно разделить по сценариям, доменным областям, степени или сложности интеграции, и т.д. Иными словами, лучше предоставить структурированный подход к ознакомлению с вашей документацией. В идеале читатель должен идти по Шагам, на каждом из которых он должен достигать очередной небольшой цели, а некоторые мог бы и пропустить. Так, процесс интеграции будет более простым и даже увлекательным.
Потребитель API должен смочь выбрать какие части документации ему нужны.
История изменений
В среде Open Source разработки существует техника, называемая «Лог изменений» (Change Log). Её можно и нужно применять к документации, так как это позволит потребителю легко и быстро понять насколько актуальной версией он пользуется сейчас, нужно ли ему озаботиться переходом на более свежую версию, и так далее. Для этого достаточно коротко описать изменения и номера версий продукта, а также дать ссылки на страницы, где можно почитать об этих изменениях подробнее.
Длинный лист изменений может означает что ваш API недостаточно стабилен, но также может означать, что оно активно поддерживается и развивается. Не стоит скрывать историю, наоборот, стоит явно её показывать.
Предварительные договорённости
Процесс интеграции обычно требует предварительных договорённостей, иногда контрактов, технической и юридической подготовки. Это может быть:
- Подписание соглашений и контрактов, связанных с оплатой и безопасностью
- Обсуждение деталей несколькими способами коммуникации (e-mail, созвоны и чаты, и т.д.)
- Обмен сертификатами безопасности, предварительно сгенерированными документами (это то, чего требует стандарт SAML, к примеру) и т.д.
С технической точки зрения может понадобиться:
- Установка безопасного соединения между клиентом и сервером, добавление IP адресов в «Белые списки», налаживание VPN и т.д.
- Генерация кода клиентов API
- Добавление тестовых данных для тестирования и сертификации разработки перед выводом её в продакшен
Это может быть не полный список того, что может понадобиться сделать вам. Не стоит думать, что клиенты обо всём догадаются сами. Стоит прямо и прозрачно описать весь этот процесс в документации, желательно разбив его на фазы или шаги.
Эта часть документа описывает с чего нужно начать и должна ответить на вопросы:
· Кто будет инициировать процесс интеграции (команда разработки или это должно быть сначала утверждено кем-то из менеджмента)?
· Может ли ваш API быть использован любым «странником Интернета» или это требует дополнительных бюрократических процедур?
· И т.д.
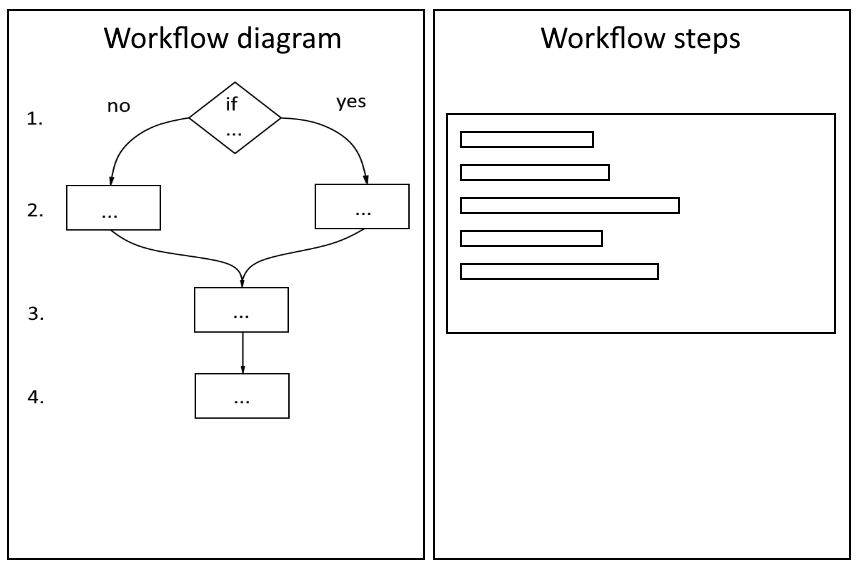
Будет отлично представить план не только в тексте, но и в диаграмме
Цикл внедрения
Диаграммы. Детали каждого шага. Примеры кода. Всё важною – не останавливайтесь лишь на чём-то одном. Однако, убедитесь, чтобы все эти части говорили об одном и том же и не конфликтовали – это часто заводит в тупит, усложняет и замедляет интеграцию, а также выставляет вас с не очень хорошей стороны.
Иными словами, каждая следующая часть документа должна дополнять и подтверждать правильностей предыдущей.
К примеру, очень удобно, если после прочтения полной «дорожной карты» (road map) интеграции, я смогу заглянуть на диаграмму и ответить себе на вопрос a “насколько далеко я от цели и какой мой следующий шаг?”. А после просмотра диаграммы, я могу заглянуть в примеры кода и убедиться в том, что учёл все необходимые правила валидации полей данных.
Если вы используете протоколы или алгоритмы, которые являются стандартом индустрии – обязательно приложите ссылки и упомяните это в документации.
Валидация
Форматы данных и правила валидации, пожалуй, наиболее часто забываемые части, но также одни из самых важных. Никто не захочет выступать для вас в роли тестировщика (по крайней мере, не стоит на этой надеяться). Поэтому, когда разработчик делает всё по документации, но в итоге в ответ на API запрос получает ошибку, о которой ни слова в документации, то возникает множество вопросов и страхов о том «Чего ещё можно ожидать от такого API?» Это съедает много времени на уточнение и лучше, чтобы вы сами озаботились этим заранее.
Схема валидации может быть представлена как в виде файла (JSON, YAML – автоматически читаемые некоторыми API клиентами, и т.д.), так и в виде текстового описания. А лучше в обоих.
То же самое касается ограничение использования вашего API (Limits). Если есть какой-то шанс того, что ваш потребитель должен в некоторых случаях заплатить больше обычного, или может быть попросту заблокирован или ограничен в услугах – это должно быть явно сказано в документе, а не позже, во время использования на реальных окружениях.
Тестовые данные
В лучших примерах документации, девелоперам предоставляются простейшие команды (cURL, к примеру), которыми можно прямо в консоли быстренько проверить соединение к API. Это подразумевает, что ваши сервера имеют некое тестовое окружение с предварительно подготовленными тестовыми данными, которые не страшно «сломать» случайно неверно выполненной командой.
Честно говоря, я никогда не видел, чтобы вендоры предоставляли это сразу и по умолчанию, хотя это так очевидно. Обычно, приходится отдельно запрашивать и договариваться об этом. Но так как мир стремительно мчится в сторону повсеместного использования автоматического тестирования и доставки (Если термины TDD, unit-testing, mocking, API virtualizing, CI/CD pipeline ничего вам не говорят, то есть шанс многое узнать погуглив).
Термины
Абсолютно нормально использовать специфическую терминологию из вашей доменной области, особенно если API не доступно каждому встречному. Однако, надо не забывать «взвешивать знания» вашего потенциального потребителя, и оценивать насколько уместно с ним говорить «на своём птичьем языке».
Будет отлично оставить список с расшифровкой всех используемых терминов. Конечно, для этого может потребоваться значительная работа и нужно уметь ставить себя на место другого человека. Но помните, что качественный код, это не тот код, который никто не может прочитать. То же самое, можно отнести и к документации.
Снижайте уровень недопонимания между вами и вашими потенциальными потребителями, ведь это снизит «порог вхождения» и привлечёт к вам гораздо больше бизнес-клиентов.
Также важно
Не забывайте спрашивать о фидбеке. Это отличная идея, после успешной (и ещё важнее – после неуспешной) интеграции, задать клиенту несколько вопросов:
- Насколько понятной была документация?
- Как много времени у вас отняло начально ознакомление с документацией?
- Насколько быстро вы составили для себя первый список вопросов и дорожную карту интеграции?
- Как много вопросов вам пришлось выяснить помимо чтения документации? Какие вопросы?
- И т.д.
Этот маленький опросник даст вам много пищи для размышления и позволит заранее подумать о многих вопросах, которые действительно волнуют потребителей вашего API, а не вас самих.
Спасибо!



Комментарии
Отправить комментарий